パナソニックHD、視覚情報を言語で理解するAIモデルを約2倍高速化する技術「SparseVLM」を開発



開発の背景
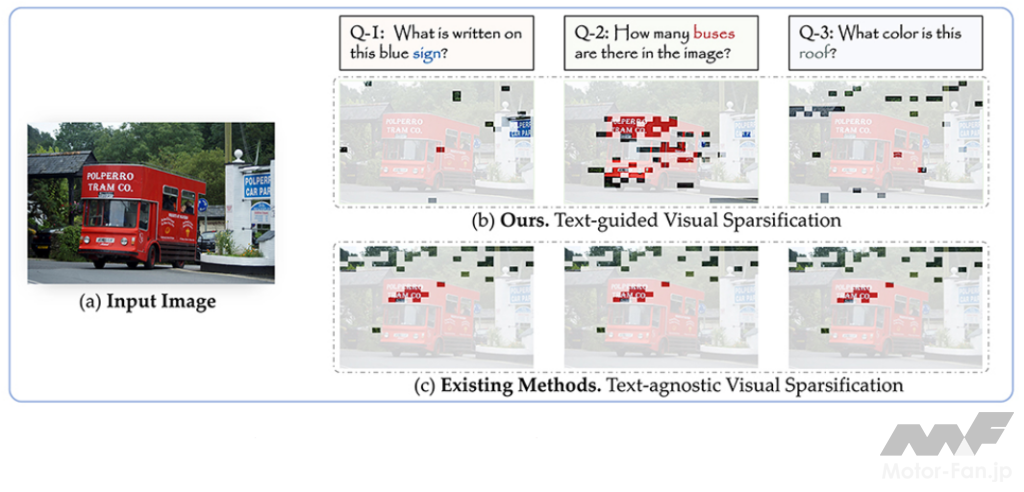
近年、視覚情報とテキスト情報を同時に処理し、視覚情報に対する質問に回答するAIモデルであるVLMが盛んに開発されているが、特に高解像度の画像や長時間の映像では、AIモデルが扱う情報量が増えるため、推論時間や演算量が増大してしまうという課題がある。開発された「SparseVLM」は、入力したプロンプトに関連する視覚情報のみを処理(スパース化)するという新たなアプローチ(図1)により、画像に対する高い質問応答精度を維持しつつ、推論時間や演算量を大きく削減することに成功した。
本技術は、先進性が国際的に認められ、AI・機械学習技術のトップカンファレンスであるThe 42nd International Conference on Machine Learning(ICML 2025)に採択された。2025年7月13日から2025年7月19日までカナダ バンクーバーで開催される本会議で発表される。
技術の内容
パナソニックHDとPRDCAでは、今回の研究を実施した大学と共同で高効率な生成AIに関する研究が進められている。昨今、大規模言語モデル(Large Language Model、以下、LLM)の持つ高い論理的推論能力や認識能力を活用すべく、LLMを組み込んで視覚情報とテキスト情報を同時に処理するVLMが注目されている。しかしながら、これらのモデルは画像や映像から抽出した視覚特徴をテキスト特徴と統合してLLMへ入力する構造であることから、特に高解像度の画像や長時間の映像では、LLMが扱う情報量が増え、回答の生成に不要な視覚特徴も処理する必要があり、推論時間や演算量が増大してしまうという課題がある。
このような視覚特徴の冗長性に着目してVLMを軽量化する手法が他にもいくつか提案されているが、これらの既存手法は画像のみから処理する視覚特徴を選択しており、入力したテキスト情報(プロンプト)との関係性を考慮せず軽量化を行う。そのため、プロンプトに関連しない視覚特徴も処理しているという点で非効率的であり、改善の余地が残っている。
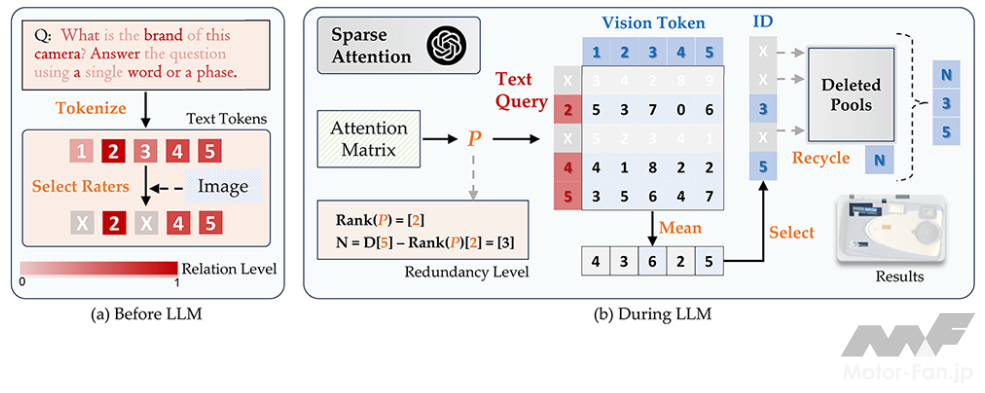
これに対し、「SparseVLM」は、入力したプロンプトに関連する視覚特徴のみを処理し、それ以外の特徴を削減(スパース化)するVLM軽量化手法を提案した。具体的には、プロンプトから入力した画像や映像に関連する単語を選択した上で、選択された単語に関連する視覚特徴のみを処理する(図2)。これにより、例えば「青い標識には何と書いているか?」という質問に対して、画像中の右上の標識の領域に注目して回答するなど(図1中Q-1)、入力したプロンプトに応じて回答に必要な視覚特徴のみを選択して効率的に処理することが可能。さらに、ほとんどの既存手法は、軽量化するためにデータセットを準備して追加で学習することが必要であるのに対し、提案手法は追加の学習不要で軽量化可能であることも大きなメリットと言える。
評価実験では、8種の画像に対する質問応答ベンチマークにおける性能を既存手法と比較された。その結果、軽量化前のモデルに対して平均89.3%の精度を維持しつつ、48.3%の高速化および71.9%の演算量抑制を達成し、既存手法に対する優位性が確認された。(図3)
今後の展望
今回開発された「SparseVLM」は、従来のVLM軽量化手法では考慮されていなかった入力プロンプトを考慮することで、質問応答精度を保ちながら処理速度を約2倍に高速化する技術。ユーザの状態や周辺環境を視覚情報から高速に認識し、言語化することが求められる多くの分野での活用が期待される。





